本文内容来源于2026年1月31日Sarah Hinchliff Pearson在德国法兰克福维基媒体未来实验室发表的“how to keep the internet human”主题演讲。Sarah曾任知识共享组织Creative Commons资深法律顾问,在知识产权领域深耕15年。
导语
打开手机,我们习惯了随手转发文章、引用资料、下载图片,仿佛互联网上的一切,都可以“免费取用、随意复用”。但很少有人意识到,这种无边界的“自由共享”,正在慢慢消耗我们分享知识的意愿,让曾经充满人文温度的互联网,逐渐变成一片没有规则的荒原。
一、别再误解“开放”了,我们都错了
作为一名“懂法律的作家”,作者Sarah Hinchliff Pearson在知识产权领域深耕15年,曾是“开放运动”的坚定支持者——反对过度严苛的知识产权法,主张让知识自由流动。但久而久之,她发现了一个问题:我们一味追求“开放共享”,却忽略了“合理边界”的重要性,最终让“共享”变成了“滥用”。
很多人会把这一切归咎于AI,但事实上,正如隐私学者Daniel Solove所说“AI的行为,只是数字时代以来数据收集和使用的延续”,它没有创造新问题,只是让旧问题变得更突出。
这背后,是我们对“开放知识(open knowledge)”的认知出了偏差。长久以来,我们陷入了几个误区:总觉得“开放”就是毫无限制,把“不能私有”和“无需规则”画上等号;过分纠结于版权的边界,却忘了分享的本质是“互利共赢”;用单一的标准定义“开放”,把它变成了一道“纯度测试”,反而偏离了知识共享的初衷。
二、划重点,边界才是共享的底气
其实,真正健康的知识共享,从来不是“无拘无束的免费取用”,而是像一个“共享牧场”——需要大家共同遵守规则,才能保证牧场不被过度消耗,每个人都能从中受益。这就是“共享资源”的核心:有边界的共享,才能让分享的循环持续下去;没有规则的自由,只会让所有人都失去分享的动力。
要改变这种现状,我们首先要更新对“开放知识”的认知:那些旧的分类方式已经过时了,线上的一切内容都可能被机器当作数据使用,再纠结于“开放内容(open content)”和“开放数据(open data)”的区别,已经没有意义;版权不再是我们的主要敌人,它的薄弱之处,恰恰让机器复用变得毫无约束;我们更不能把“财产权(property)”和“道德(morality)”混为一谈——就算知识不能被私有,也不代表可以无底线滥用。
边界,从来不是“开放”的敌人,而是“共享”的保障。就像我们在公共场合也需要隐私一样,创作者分享内容时,也期待自己的作品被合理使用,而不是被用于有害用途,或是被抹去来源、无偿获利。这种边界,能让分享者感受到尊重,也能让知识共享形成“互利循环”:追求知识→愿意分享→遵守规则→集体受益→继续追求知识。
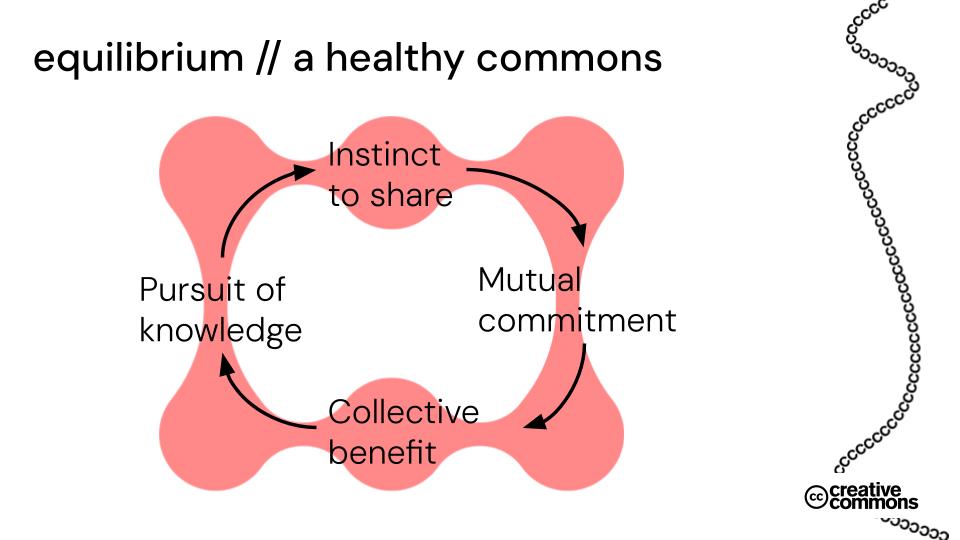
知识共享的一致性
图片来源:https://creativecommons.org/2026/02/12/how-to-keep-the-internet-human/
三、如何实操重建健康共享环境?
那么,我们该如何重建这种健康的共享环境?其实答案很简单,就是在“开放”和“约束”之间找到平衡。具体来说,有几个方向值得我们关注:
署名(Attribution)仍然是最基本的要求。注明内容来源,这既是对创作者的尊重,更关系到信息来源、知识脉络,是保证信息真实的基础;
互惠(Reciprocity)是重要原则,那些从他人作品中获取知识的人,也有责任让自己的成果被他人取用,形成良性循环;
财务可持续(Financial sustainability)是前提,要让知识的生产者获得合理回报,才能保证有更多优质内容被分享;
禁止有害使用(Prohibitions on harmful use cases)是底线,有些用途会对他人或社会造成伤害,理应被排除在“合理复用”之外。
公开分享意味着什么?答案不在于完全封闭,也不在于无条件开放,而在于建立既保护创作者又促进知识流动的智慧边界。这需要勇气放弃非此即彼的思维,拥抱更复杂、更人性化的解决方案。如社会学家鲁哈·本杰明提醒我们的:“需要让那个在我们想象力边界巡逻的、愤世嫉俗的牢骚者休息一下。”
参考链接:
https://creativecommons.org/2026/02/12/how-to-keep-the-internet-human/
 -
- -
-
