近日,Digital Science(数字科研)公司的Research Futures副总裁Simon Porter发表了一篇题为“《巴塞罗那宣言》...探讨我们作为元数据使用者的责任”的文章,深入分析了开放元数据(Open metadata)的使用原则以及我们在研究生态系统中应承担的责任。通过强调永久标识符(Persistent identifiers)的重要性和不同类型元数据的处理方法,文章指出了当前元数据管理中的挑战和未来改进的方向。本文将引导您深入了解如何在开放科学环境中负责任地使用元数据,并推动更透明和可信的研究信息系统(RIS)的发展。
核心观点
元数据类型及其处理方式:
1.开放型元数据:以开放研究原则创建,具有高透明性和可追溯性。
2.算法增强的元数据:通过算法处理生成,可能存在准确性未知和来源不明的问题。
3.机构增强的元数据:通过机构内部流程进行处理和改进,以满足机构自身(例如大学)和政府报告的需求,包含额外的元数据信息。
元数据使用责任:
1.使用元数据时需要考虑其来源和背景信息,以确保其在新的环境中依然保持准确性。
2.机器生成的元数据需要经过人工审查或验证后才能在原系统外传播和使用,以避免数据失效或误用。
3.评估科研表现的排名系统应独立于其所使用的数据聚合来源,以避免对特定平台的依赖和数据质量问题。
背景:
2024年4月16日,巴黎萨克雷大学、索邦大学、乌得勒支大学、比尔及梅琳达·盖茨基金会、法国国家科研署(ANR)、EOSC(欧洲开放科学云)协会等超过40家科研机构、科研资助和科研评估机构共同签署了《开放研究信息巴塞罗那宣言(Barcelona Declaration on Open Research Information)》(以下简称《巴塞罗那宣言》)。该宣言的基本前提是“研究信息领域需要根本性变革(The research information landscape requires fundamental change)”。因此,签署机构承诺率先改变研究信息的使用和生产方式:研究过程和交流的信息应该公开透明,并成为一种新常态(Openness of information about the conduct and communication of research must be the new norm)。公开的研究信息使得科学政策决策可以基于透明且全面的数据基础,确保了研究评估过程中使用的信息对评估对象来说易于获取和核查。这些也进一步推动了全球向开放科学转型,保障了所用信息的完全公开和透明。
签署《巴塞罗那宣言》的机构承诺如下内容:
1.我们将把开放作为我们使用和生产研究信息的默认选择;
2.我们将与支持和促进开放研究信息的服务和系统合作;
3.我们将支持开放研究信息基础设施的可持续发展;
4.我们将支持集体行动,加速向研究信息开放的转变。
文章正文:
《巴塞罗那宣言》在第一项承诺中指出“我们将把开放作为我们使用和生产研究信息的默认选择”,但“我们”指的是谁,这对于理解研究生态系统中的各个角色及其相应的责任至关重要。在数据生产、使用和聚合的过程中,资助者、出版商、基础设施服务提供者、研究机构以及研究人员各自以不同的方式与数据互动。
《巴塞罗那宣言》可能是第一份界定研究生态系统中社群在开放元数据使用方面责任的文件。然而,这只是一个开始。我们坚信,深入理解研究生态系统各组成部分的具体需求,对于赋予《巴塞罗那宣言》实际操作性,并推动我们迈向一个更加开放的元数据环境尤为重要。实际上,只有当我们致力于在实际工作中应用开放元数据,并让其塑造我们在研究领域的互动模式时,开放元数据的价值才能真正体现。
然而,对开放元数据使用的承诺要求我们密切关注所使用的元数据类型、应用的背景以及对他人的期望。如果不明确阐明我们作为研究元数据创建者和使用者的角色,可能会导致研究环境开放但是缺乏信任。
元数据类型并非千篇一律
生产和使用(以及聚合)元数据之间存在本质上的不对称性。虽然与创建元数据相关的责任相对容易界定,但与使用和聚合元数据相关的责任却未被充分探讨,原因在于它们尚未成为紧迫的问题。实际上,《巴塞罗那宣言》明确指出,我们已经达到了一个必须考虑这一问题的转折点。我们认为,与元数据使用相关的责任具有情境依赖性,它取决于元数据本身的来源,并且需要为每个参与者和使用案例明确这些责任。因此,在《巴塞罗那宣言》的背景下,探讨元数据的不同创建方式及其对使用者可能产生的责任,具有重要的现实意义。
《巴塞罗那宣言》中至少暗示了三种不同类型的元数据记录:
开放元数据记录
开放元数据(Open metadata)记录指的是那些从创建之初就遵循开放研究原则的元数据。例如,依据这些原则创建的出版物会将关联每个研究者的ORCID(研究人员标识符)和每个机构的ROR ID(研究机构标识符)。在出版物的正文及其元数据中,资助机构会与其开放资助者注册ID(Open Funder Registry ID)或ROR ID相关联,而资助信息本身则将与开放的、永久标识的资助记录相关联,例如通过Crossref的基金链接系统(Crossref grant linking system)。出版物本身(以及其丰富的元数据表示)将与DOI相关联,所有参考文献的DOI也将公开可用。当我们提及“开放”时,我们指的是这些数据采用CC0许可(即“权利释放”许可)。在论文中,我们可能会遇到指向数据存储库的其他链接,以及其他表明论文来源和符合良好研究实践标准的信任标记(Trust markers)。对于资助、数据集、研究软件代码和其他研究对象,我们也持有类似的期望。
算法增强的元数据记录
算法增强的元数据记录是指利用算法对原始数据进行加工后得到的信息元素。这些算法可能并不公开,其采用的方法可能不为人知,而且元数据的准确性也可能是未知的。这是当今许多分析中的一个隐藏变量——通常假设文章数据可能存在统计偏差,而元数据则没有偏差。随着时间的推移,许多出版物的记录可能不再满足现行的元数据开放标准。这可能是因为当时没有相应的技术或标识符基础设施,或者是因为尚未形成完善的元数据实践。对于这些不符合开放标准的元数据记录,可使用算法通过标识符来增强其信息。一个突出例子是用于识别机构隶属关系和重建研究人员身份的算法。算法还可用于通过添加链接到原始元数据中不存在的外部研究分类(External research classifications),来增强记录的描述性。
随着大语言模型(LLM)和其他人工智能系统变得更易获取且成本降低,这类数据的普及程度可能会逐渐增加。因此,在未来几年中,元数据可能会有统计上产生的不准确性。如果这些不准确性在关键分析中被证明是可以忽略不计的,那么整个社会可能会忽略这些不准确性。
机构增强的元数据记录
机构增强的元数据记录是指通过机构内部流程进行处理和改进,以满足机构自身(例如大学)和政府报告的需求而设计的元数据。这些记录汇聚自多种来源,或经过手动整理,可能包含额外的元数据。例如,论文作者可能与特定的机构ID建立关联,而新增的研究分类可能包含与数据集的链接。这些机构记录既可以通过机构库(Institutional profiles)公开,也可以与其他州级或国家级计划共享。
使用元数据时,我们的责任是什么?
《巴塞罗那宣言》将我们上面定义的三种类型的元数据视为同等重要:在CC0许可下共享,允许不受限制地重复使用。撇开许可问题不谈,我们应根据元数据的来源来决定其重复使用的方式。
在探讨如何实现《巴塞罗那宣言》的目标时,我们需要认真考虑一种整体性的策略方法,以应对信息再利用相关的责任问题。正如宣言所指出的,我们提出这些建议,旨在作为讨论的起点而非最终结论。这些责任的完善需要通过社区的广泛讨论来实现。
责任1.元数据的预期用途必须对其解释的方式以及适用的地理、学科或时间范围进行限制,以确保其被负责任地使用
在关注数据开放性的同时,也需要考虑所传播元数据的背景信息。元数据是为了特定目的而生成的,这一目的不仅决定了元数据的准确性和使用时的谨慎程度。此外,它还界定了保持其准确性的限制条件和相关责任。
对于机构来说,《巴塞罗那宣言》明确指出,当前研究信息系统(Current Research Information Systems,CRIS)是实现研究信息开放的一种机制。该宣言强调,所有相关研究信息应通过标准协议和标识符(如适用)进行导出并公开。这一要求源于2010年左右由NIH资助的VIVO和Harvard Catalyst profiles(研究人员档案数据库)项目所推动的运动。这些公共档案(Public profiles)的主要用途是在机构、州或国家层面上帮助寻找专家。这一运动的核心在于,原本为内部报告和行政目的而收集的信息,同样可以用于创建公共档案——一个信息源能够高效地服务于多种用途。在某些情况下,CRIS整合信息的方式被进一步用于创建州级门户网站,如俄亥俄创新交流平台(Ohio Innovation Exchange),或国家级的开放研究分析平台,如丹麦研究门户(Research Portal Denmark)。尽管这些做法已经取得了成效,但这些记录的来源特性意味着在这些特定应用之外重新利用这些信息存在实际使用中的一些局限性。
CRIS这一术语蕴含了一个关键的局限性。CRIS旨在维护、更新或聚合有关“当前(Current)”研究人员的数据。对于机构而言,并无义务维护前雇员的公开信息。实际上,从专家发现的角度来看,以相同方式呈现这些档案可能会造成一定的麻烦或不便。
在CRIS系统中,元数据的收集往往带有政治动机,例如为了向选民展示研究的价值,这通常通过政府报告形式体现国家目标。然而,当这些元数据在更广泛的背景中使用时,可能会出现元数据记录存在偏差、不完整的情况。例如,为满足国家层面报告需求的出版物可能非常准确地记录一个该国研究人员的所属机构,但对于国际合作的机构,则可能因为与该国报告关系不大,其记录的准确性会大大降低。
记录也可能以其他方式存在偏差。研究可以根据特定报告任务的目标进行分类,因此这种偏差会体现在所应用的分类标准、维持这些分类所需的时间和努力,以及分类所涵盖的研究范围。如果要在不同的背景下重用这些分类元数据,那么在记录这些分类元数据时必须保留并且充分理解其背景或来源(Provenance)信息。
《巴塞罗那宣言》可能隐含的一个含义是,所有元数据的管理都必须基于其将在更广泛的研究社区中长期使用的认识。若此为预期的解读,那么我们应该对这项工作所需的额外努力有一个现实的认识。具体来说,这不仅涉及额外的工作量,还包括为数据管理方法的编纂和文档化而需要建立的相关结构或机制。这一解释还会立即引出几个实际问题:存储和传递元数据记录是否意味着负有持续更新的责任?这种解读会对更广泛的研究群体造成何种不平等?是否会使“元数据丰富”的群体(那些有能力投资于改进记录的群体)受益,而让“元数据贫乏”的群体(那些缺乏完善机制或事后机制来管理元数据的群体)处于不利地位?这些担忧并非空穴来风,因为目前非洲研究的可见性不足,已经妨碍了我们全面理解、评估和加强非洲国家对促进知识发展的重要投资的努力。
当然,已经有一些解决办法来应对开放机构元数据引发的诸多持续性问题。其中一种机制是通过ORCID将元数据的管理责任从机构转移到研究人员个人。在这种工作流程下,研究人员负责维护其公开记录的准确性,而机构则负责确认研究人员的身份和工作时间。伴随着国家推动在OA期刊和开放知识库中发表研究成果的努力,《巴塞罗那宣言》补充了国家永久标识符(PID)策略的做法,有助于这些策略朝着“PID优化的研究周期(PID-optimised research cycle)”的方向迈进。
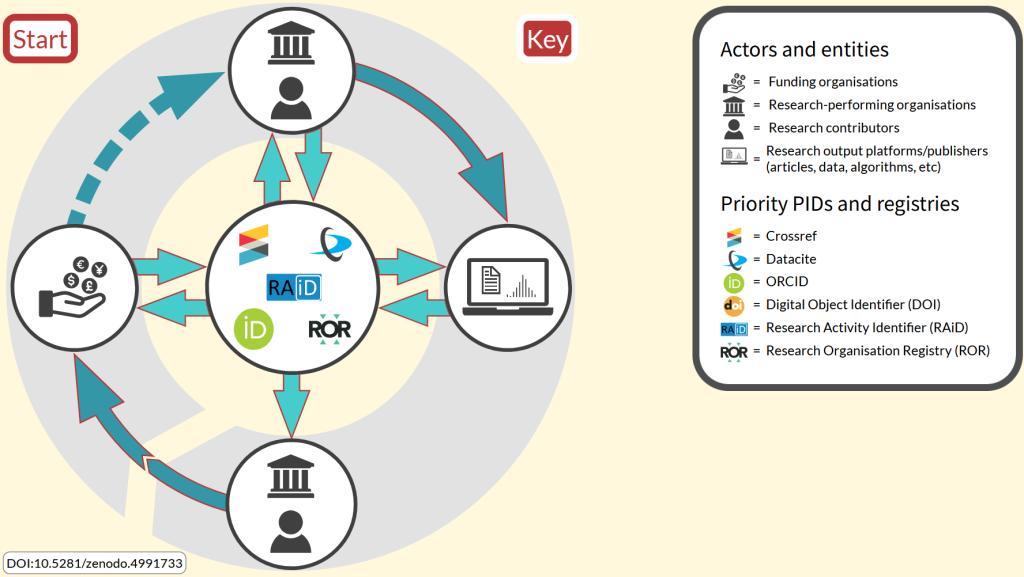
永久标识符(PID)优化的研究周期示意图
(图像来源:https://resources.morebrains.coop/pidcycle/)
责任2.不经过人工审查或验证,不应在原系统外传播机器生成的元数据
机器生成的元数据,例如将机构标识符关联到地址字符串、研究类型分类或算法确定的研究ID等,都是在一定的精确率(Precision)和召回率(Recall)的容差范围内生成的。这些容差由系统提供商根据用户需求设定。然而,每条元数据项(Individual statements)并不能保证与特定记录完全匹配。更重要的是,随着算法生成数据的方法不断改进,这些生成的数据可能会被重新生成,这可能导致之前的记录失效或变得不精确。这一概念(Notion)和思考引出了一个被忽视的元数据来源(Provenance)问题。如果缺乏相应的来源信息,元数据可能会被视为已经脱离(Escaped)其原始系统,从而面临成为“孤儿(Orphaned)”元数据的风险,这意味着这些元数据无法被更新或在新环境中适当地将其置于上下文中进行理解。当一个由算法生成的元数据记录被移出其原始创建系统的上下文时,必须对该元数据的来源(Provenance)以及使用过程中可能产生的任何推论、陈述或说明等信息(Statements)负责。这意味着要承担起确保这些元数据在新环境中仍然保持准确性和相关性的责任。虽然对于出版物来说,这可能不是个大问题(因为可以随时通过DOI请求更新版本的记录),但对于算法生成的研究者ID来说,这一点尤为重要。因为如果一个标识符指代了多位研究者,那么改进后的算法可能会显著改变该标识符所指代的研究者身份。例如,如果一个研究者记录实际上包含了两位研究者的信息,那么算法改进后的新的研究者ID可能最终会指向另一位研究者。
《巴塞罗那宣言》着重强调了采用标准化协议和标识符以促进数据共享的重要性。然而,我们应当谨慎评估元数据的出处,因为许多算法会将永久标识符与元数据记录关联起来。例如,如果使用ORCID而不是内部研究者ID来指代某个研究者,但关于该研究者的信息(Set of assertions)是通过算法生成的,那么在将这些信息传播到生成这些信息的原系统之外时,可能会损害ORCID所建立的信任模型。
责任3.排名系统应独立于其所使用的数据聚合来源
通过算法生成的元数据,常被用于进行科研表现的比较评估,这一点在排名系统中尤为明显。乍看之下,这种做法似乎与责任2(元数据应与其来源和上下文紧密结合)相冲突。然而,这种情况类似于评价机构与被评价对象(机构)之间应保持独立性的问题。不同的科学计量平台在精确度和召回率的选择上存在差异,这可能导致相同的排名方法在不同的平台上产生不同的结果。但是,排名系统往往与单一系统紧密关联,这可能导致机构在投资和数据质量反馈方面倾向于某个特定的数据源,而忽视更广泛的数据源中的其他数据集,这可能会形成一种“反向激励(Perverse incentives)”,从而影响数据的准确性和评估结果的公平性。
《巴塞罗那宣言》强调了永久标识符的一个关键优势:信息评估模型可以(也应该)在不参考特定科学计量数据集的情况下构建。通过将数据聚合与排名机制分离,我们允许新的数据聚合服务出现,而不依赖单一的“真理来源(Sources of truth)”,促进数据来源的多样性和灵活性。这样,科学计量数据源应该像大语言模型(LLM)一样,被视为极具价值,同时具备可替换性。或许,我们需要专门针对科学计量数据集,在FAIR数据原则(可发现、可访问、可交互、可重用)的基础上增加一个“可替换”(Replaceable)的原则。
将数据源与排名系统解耦还有另一个好处,即它会减少对特定系统中数据质量的(过度)投资,而是将重点放在提升数据源的质量,例如Crossref这样的机构,或优化独立的消歧算法,例如研究组织注册表(Research Organization Registry)所提供的算法。
为了构建一个独立的排名基础设施,我们不仅需要使用已有的永久标识符基础设施,还需要开发能够引用由独立机构或标准组织提供的外部分类系统或体系的功能。进一步地,在独立排名基础设施的基础上,可以考虑建立跨科学计量系统的通用查询语言(Common query language),进而促进更广泛和跨平台的科学计量研究和分析。
通过上述探讨,我们意在阐明,作为元数据的使用者,我们的责任远远超出了仅仅考虑数据使用许可或选择平台的问题。在现有的研究基础设施中,如何有效地促进开放数据的经验和方法,往往没有被纳入元数据。因此,尽管我们可以分享和使用元数据,但这些数据背后的使用方法和考虑并没有被清晰记录和传递。这意味着,我们在使用元数据时,对他人(例如其他研究人员、数据提供者)提出的要求和期望并不明确,从而影响他们对我们的分析结果或整个研究信息系统的信任度。随着《巴塞罗那宣言》从理论层面的声明逐步转向具体的实施,甚至与各国正在发展的永久标识符策略(National persistent identifier strategies)相结合,我们希望这些关于元数据使用责任的考虑,能够成为未来研究基础设施发展中的持续讨论话题。
这些讨论不仅有助于增强研究信息系统的透明度和可信度,还将推动更加开放和负责的数据共享文化的形成。

更多资讯请关注清华大学开放科学公众号
微信扫码或搜一搜“OpenSign”
阅读原文:
https://www.digital-science.com/tldr/article/the-barcelona-declaration-exploring-our-responsibilities-as-metadata-consumers/
《开放研究信息巴塞罗那宣言》:
官网:https://barcelona-declaration.org/
中文翻译文件:
https://barcelona-declaration.org/downloads/barcelonadeclaration_chinese_simplified.pdf
 -
- -
-
